

بهنظر میرسه AMD برای آیندهی کارتهای گرافیک مخصوص مصرفکننده (یعنی همون گیمینگ و خانگی) نقشههای خیلی بزرگی داره؛ و نه، چیزای معمولی و تکراری نیستن. طبق شایعات و پتنتهایی که اخیراً منتشر شدن، بهزودی شاهد کارتهای گرافیکی «چندچیپلت» از طرف AMD خواهیم بود.
البته مفهوم MCM یا «ماژول چندچیپلت» چیز جدیدی نیست، ولی بهخاطر محدودیتهایی که طراحیهای یکتکه (مونولیتیک) دارن، صنعت داره کمکم به سمت طراحیهای چندچیپلت میره. AMD هم که تو این زمینه تجربهی زیادی داره، قبلاً هم تو شتابدهندههای هوش مصنوعی سری Instinct MI200 اولین بار از طراحی MCM استفاده کرد؛ جایی که چند تا چیپ مثل هستههای گرافیکی (GPC)، حافظه HBM و چیپهای I/O روی یه پکیج کنار هم چیده شده بودن. حالا تو نسل جدید MI350، AMD یه روش تازهای رو پیش گرفته که طبق تحلیل کورتکس، شاید بشه پایه و اساس کارتهای گرافیک چندچیپلتی آینده AMD دونست.
بزرگترین چالش برای آوردن طراحی چندچیپلت به کارتهای گیمینگ، تاخیر بالای انتقال دادهست. چون تو بازیها، فریمها اصلاً با تأخیرهای طولانی کنار نمیان. برای همین AMD باید یه راهحلی پیدا میکرد که فاصلهی بین داده و پردازش رو تا جای ممکن کم کنه. طبق پتنت جدیدی که تو یکی از ویدیوها فاش شده، بهنظر میرسه AMD تونسته این مشکل رو حل کنه.

نکتهی جالب اینه که توی اون پتنت بیشتر از CPU حرف زده شده تا GPU، ولی وقتی مکانیزم و توضیحاتش رو بخونیم، مشخصه که هدفش استفاده توی کارت گرافیکه.


نحوه عملکرد طراحی چندچیپلت در GPUهای جدید AMD
اما AMD دقیقاً چطوری قراره از طراحی چندچیپلت تو کارت گرافیک استفاده کنه؟ اصل ماجرا یه مدار به اسم “data-fabric با یه سوییچ هوشمند” هست که بین چیپهای محاسباتی و کنترلکنندههای حافظه ارتباط برقرار میکنه. این در واقع همون Infinity Fabric معروف AMDـه که فقط مخصوص کارتهای مصرفی کوچیکتر شده، چون اینجا دیگه از حافظههای گرانقیمت HBM خبری نیست. اون سوییچ طوری طراحی شده که وقتی یه درخواست گرافیکی میاد، اول بررسی میکنه که آیا لازمه داده جابهجا بشه یا باید کپی بشه – اونم تو مقیاس نانوثانیه.
حالا که مشکل دسترسی به داده حل شده، پتنت میگه هر GCD (Graphics Compute Die) میتونه حافظه کش L1 و L2 داشته باشه (مثل همون کاری که تو شتابدهندههای AI کردن)، ولی علاوهبر اون، یه کش L3 مشترک (یا SRAM پشتهای) هم هست که همهی GCDها میتونن از طریق اون سوییچه بهش دسترسی داشته باشن. این باعث میشه نیاز به دسترسی به حافظهی اصلی کمتر بشه و چیپلتها راحتتر با هم ارتباط بگیرن – یه چیزی شبیه به 3D V-Cache که AMD تو پردازندههاش داره، ولی اینبار برای کارت گرافیک. از اون طرف، پای حافظه DRAM پشتهای هم وسطه که اساس یه طراحی MCM حساب میشه.
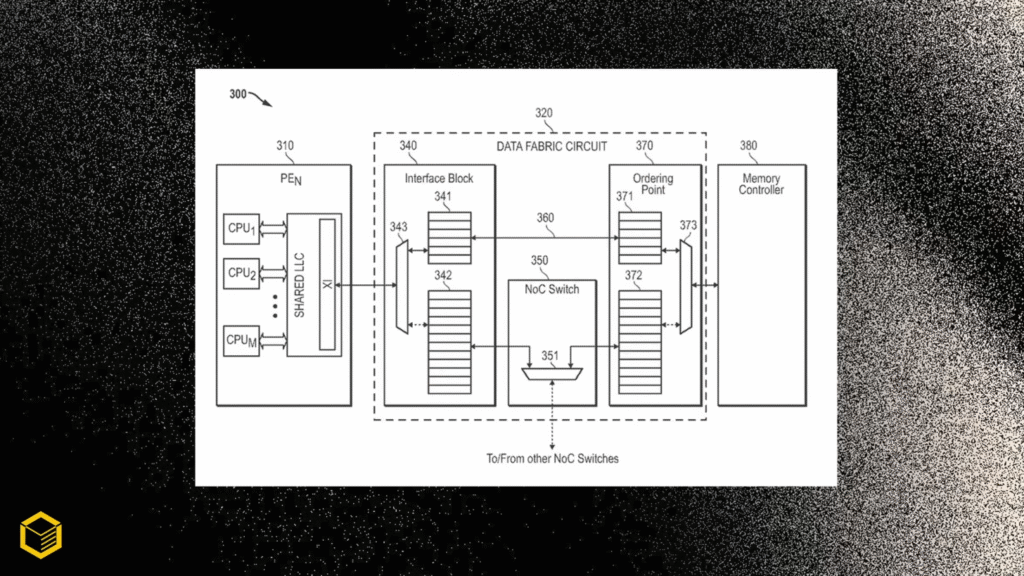
چیزی که این بار ماجرا رو جذابتر کرده اینه که AMD حالا دیگه از نظر اکوسیستم هم آمادگی کامل داره. مثلاً میتونه از تکنولوژی پل InFO-RDL شرکت TSMC استفاده کنه یا از نسخهی مخصوص Infinity Fabric برای اتصال چیپها بهره ببره. مهمتر اینه که این طراحی یه نسخهی کوچکشده از شتابدهندههای AIـه، و اگه یادتون باشه، AMD قراره معماری گیمینگ و هوش مصنوعی رو با هم ترکیب کنه و زیر یه چتر واحد به اسم UDNA بیاره. نرمافزارها و درایورهاشون رو هم یکپارچه کرده و با این کار هزینهی توسعهشون رو کم میکنه.
با محدودیتهایی که طراحیهای قدیمی دارن، صنعت کارت گرافیک نیاز به یه تغییر اساسی داره. AMD این شانس رو داره که با طراحی چندچیپلت از رقبا جلو بزنه. البته طراحیهای چیپلتی مشکلات خودشون رو دارن. مثلاً تو معماری RDNA 3 هم AMD بهخاطر تاخیر بین چیپلتها به دردسر خورد. ولی حالا با سوییچ هوشمند و کش L3 مشترک، امیدوارن این مشکل رو حل کنن. البته این یه جهش معماری بزرگه. اگه مثل من عاشق نوآوری باشین، بیصبرانه منتظرین ببینین چی میشه، ولی به احتمال زیاد باید تا معرفی UDNA 5 صبر کنیم.



